Knowledge Sources
A knowledge source is anything you point a bot at so it can answer questions about it. FluentBot supports nine source types grouped into four families — you can mix any combination on one bot.
Source Types
| Family | Sub-types | Best for |
|---|---|---|
| Website Links | URL, URL List, Crawl, Sitemap | Help centers, docs sites, public marketing pages |
| Files & Text | File upload (PDF / TXT / Markdown), pasted Text | Internal PDFs, brochures, ad-hoc snippets |
| Code | GitHub Repo, Codebase (zip) | Source code - answer questions and give examples from a repo |
| WPManageNinja | Fluent Support | Existing Fluent Support customers - answer from support tickets |
For the full add-source walkthrough, see Train your bot.
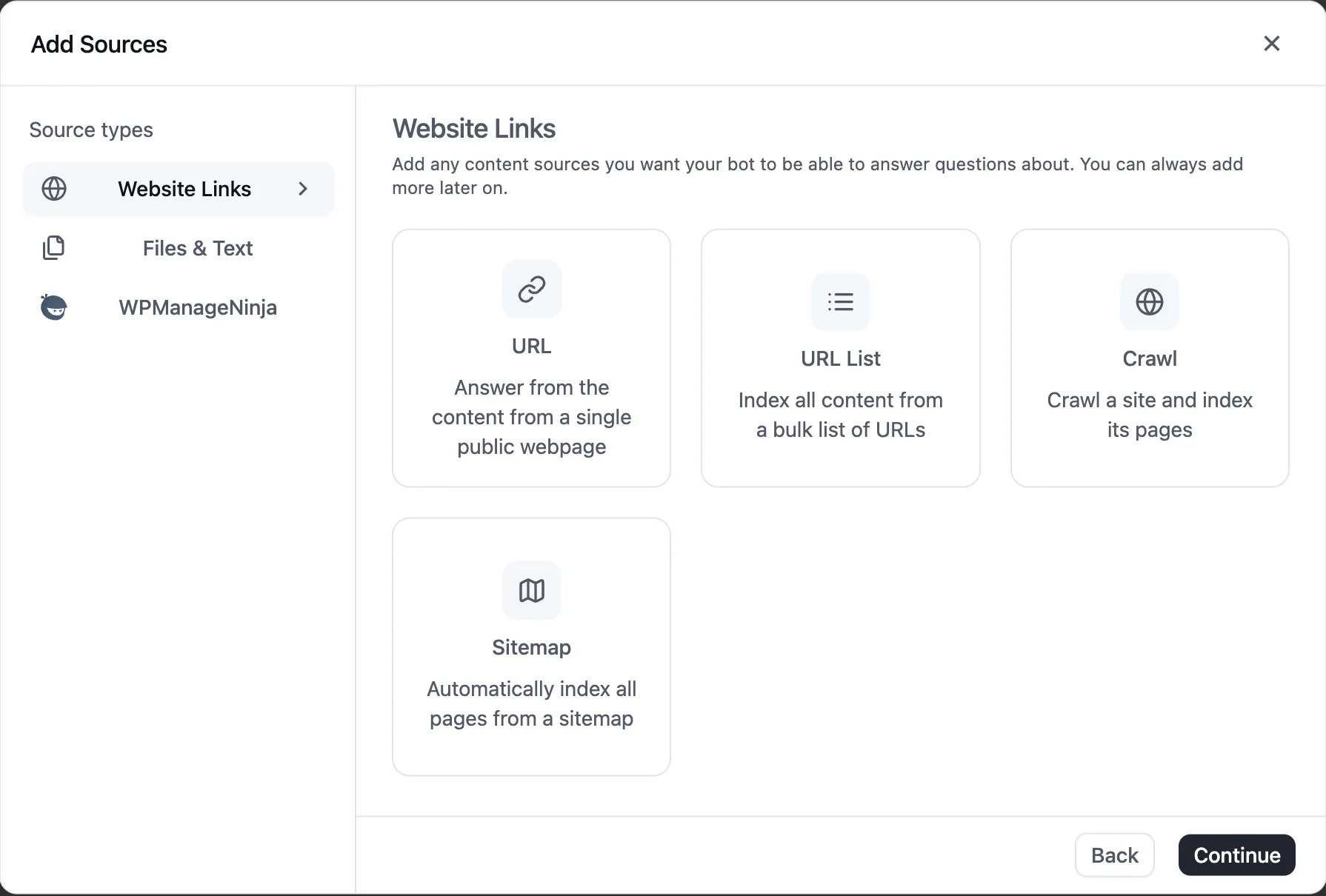
Website Links
Website Links fetch public web content and turn each page into one or more documents. You can set them to re-check on a schedule: Never, Daily, Weekly, or Monthly.
Use the bot’s Blocked URLs list to prevent specific pages or paths from being indexed.
URL
Use URL when you only need one public page, such as a landing page, policy page, or single help article.
Form fields:
- URL - the absolute page URL.
- Source title - optional display name. Defaults to the page title or URL.
- Scheduled refresh - how often FluentBot should re-check the page.
Best fit:
- One page has the exact answer content.
- You want tight control over what the bot learns.
- A broader crawl would include low-value pages.
URL List
Use URL List when you already know the exact pages to index. Upload a .txt or .csv file containing one URL per row.
Form fields:
- File - a TXT or CSV list of public URLs.
- Source title - optional display name. Defaults to the uploaded filename.
- Scheduled refresh - how often FluentBot should re-check listed URLs.
Best fit:
- Curated docs pages.
- A subset of a large site.
- A manually reviewed list from another system.
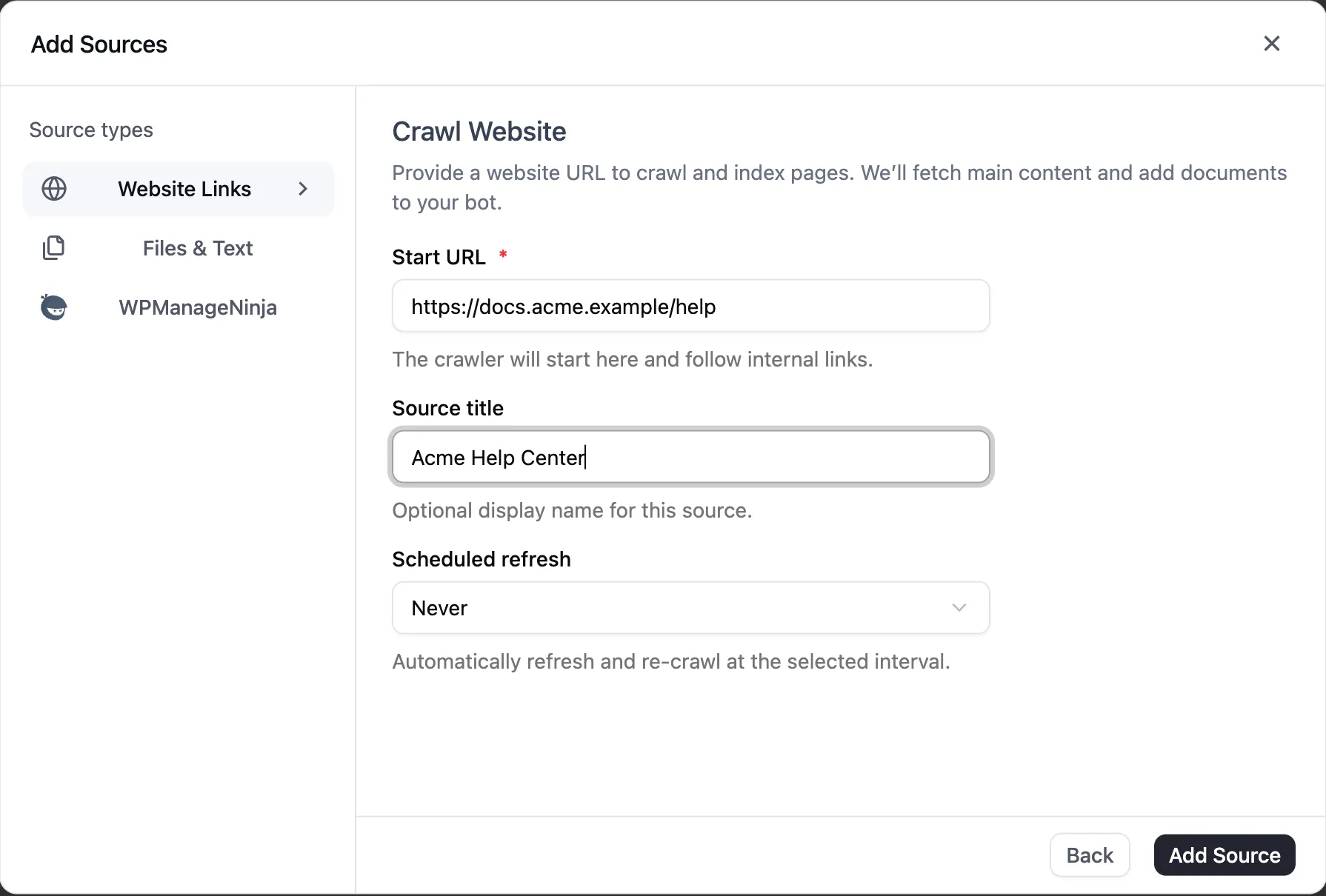
Crawl
Use Crawl when you want FluentBot to start from one URL and follow internal links.
Form fields:
- Start URL - where the crawler begins.
- Source title - optional display name. Defaults to the URL.
- Scheduled refresh - how often FluentBot should re-crawl.
What gets crawled:
- Internal links reachable from the start URL.
- Pages on the same site area, subject to crawler limits and blocked URLs.
- HTML pages with readable public content.
What is skipped:
- External domains.
- Blocked URLs.
- Login-only pages.
- Non-HTML assets such as images, videos, and downloads.
Prefer Sitemap over Crawl when a clean sitemap exists. Sitemap is faster and avoids accidental discovery of unrelated sections.
Sitemap
Use Sitemap when a site publishes a sitemap.xml that lists the pages you want indexed.
Form fields:
- Sitemap URL - the absolute URL of the sitemap file.
- Source title - display name in the sources table.
- Scheduled refresh - how often FluentBot should re-fetch the sitemap.
Most sites publish sitemaps at one of these locations:
https://example.com/sitemap.xmlhttps://example.com/sitemap_index.xml- Listed in
https://example.com/robots.txtunderSitemap:
If a sitemap index contains multiple sub-sitemaps, point FluentBot at the specific sitemap you want. This avoids indexing unrelated pages.
Sitemap quality matters:
- Stale URLs can fail during indexing.
- Missing URLs won’t be indexed.
- The wrong sub-sitemap can train the bot on unrelated content.
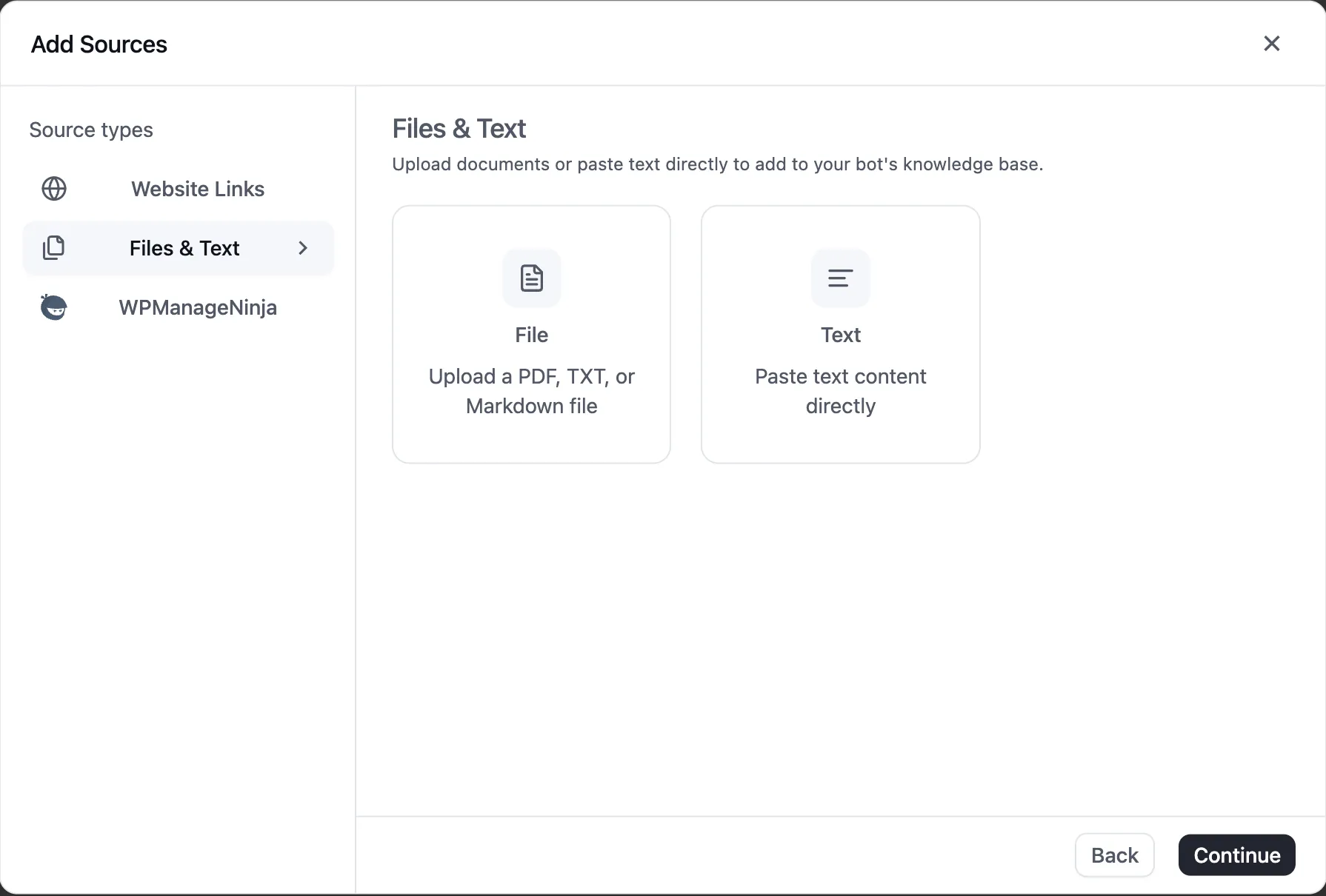
Files & Text
Files and Text sources are for content you already have. They don’t have scheduled refresh — FluentBot can’t know when your local file or pasted text changes.
File
Use File for PDFs, TXT files, and Markdown files.
Supported formats:
- PDF - text-based PDF documents.
- TXT - plain text.
- Markdown -
.mdfiles, with structure preserved as text.
Form fields:
- File picker - drag-and-drop or choose a file.
- Source title - optional display name. Defaults to the filename.
Files are limited to 20 MB at upload time.
To replace a file, delete the old File source and upload the updated file. FluentBot doesn’t edit uploaded files in place.
If a file extracts poorly, convert it to Markdown or paste the corrected text as a Text source.
Text
Use Text for short or medium content that is easiest to paste directly, such as policies, FAQs, canned instructions, or internal notes.
Form fields:
- Title - required display name.
- Content - pasted source text.
Text is usually the fastest way to add a small amount of reliable information. It’s also useful when a web page or PDF extracts poorly.
To update Text content, delete the old source and add a new Text source with the corrected version.
Fluent Support
Use Fluent Support when your team already has support tickets in a WordPress site running Fluent Support.
Form fields:
- Domain - the WordPress site domain.
- Username - a WordPress user with the required access.
- Application Password - a WordPress application password.
- Ticket status - ticket statuses to include.
- Product - product scope for imported tickets.
- Tags - optional tag filter.
- Date filter - optional date scope.
- Refresh schedule - how often FluentBot should sync matching tickets.
FluentBot fetches matching tickets from the Fluent Support API and adds the resulting ticket content to the bot’s knowledge base.
Code
Code sources index a software repository so the bot can answer questions about your codebase and produce code examples. There are two ways to add code.
GitHub Repo
Connect a GitHub account through the FluentBot Connector app, then pick a repository. FluentBot reads the selected branch and indexes its source files.
Form fields:
- GitHub account - a connected account or organization. Use Connect another to add more.
- Repository - the repo to index. Only repositories you grant access to during install appear here.
- Branch - defaults to the repository’s default branch.
- Source title - optional display name. Defaults to the repository name.
- Scheduled refresh -
Never,Daily,Weekly, orMonthly. On refresh, FluentBot re-checks the repo and re-indexes only the files that changed.
Connecting is a one-time install per account. See FluentBot Connector for the GitHub App, its permissions, and privacy details. Manage or disconnect connected accounts from the GitHub tab on the Knowledge Base page.
Codebase (zip)
Upload a .zip of your source code when you would rather not connect GitHub.
Form fields:
- Codebase archive - a
.zipfile, up to 50 MB. - Source title - optional display name. Defaults to the archive name.
Zip uploads have no scheduled refresh. To update, upload a new zip - FluentBot compares it with the previous version and re-indexes only the changed files.
What gets indexed
For both code source types, FluentBot automatically skips noise and sensitive files:
- Dependency and build directories such as
node_modules,vendor,dist,build,__pycache__,.venv, andtarget. - Lockfiles and generated or minified output such as
package-lock.json,*.min.js, and*.map. - Binaries and media such as images, fonts, archives, and compiled artifacts.
- Secret files such as
.env,*.pem, private keys, and credentials. Any secrets detected inside code are redacted before indexing.
Each indexed file becomes one document. For public GitHub repos, citations link to the file on GitHub; for private repos and zip uploads the file path is shown without a link, so nothing private is exposed.
How sources become usable
Every source follows the same high-level path: add the source, wait for it to finish processing, then test answers in Playground.
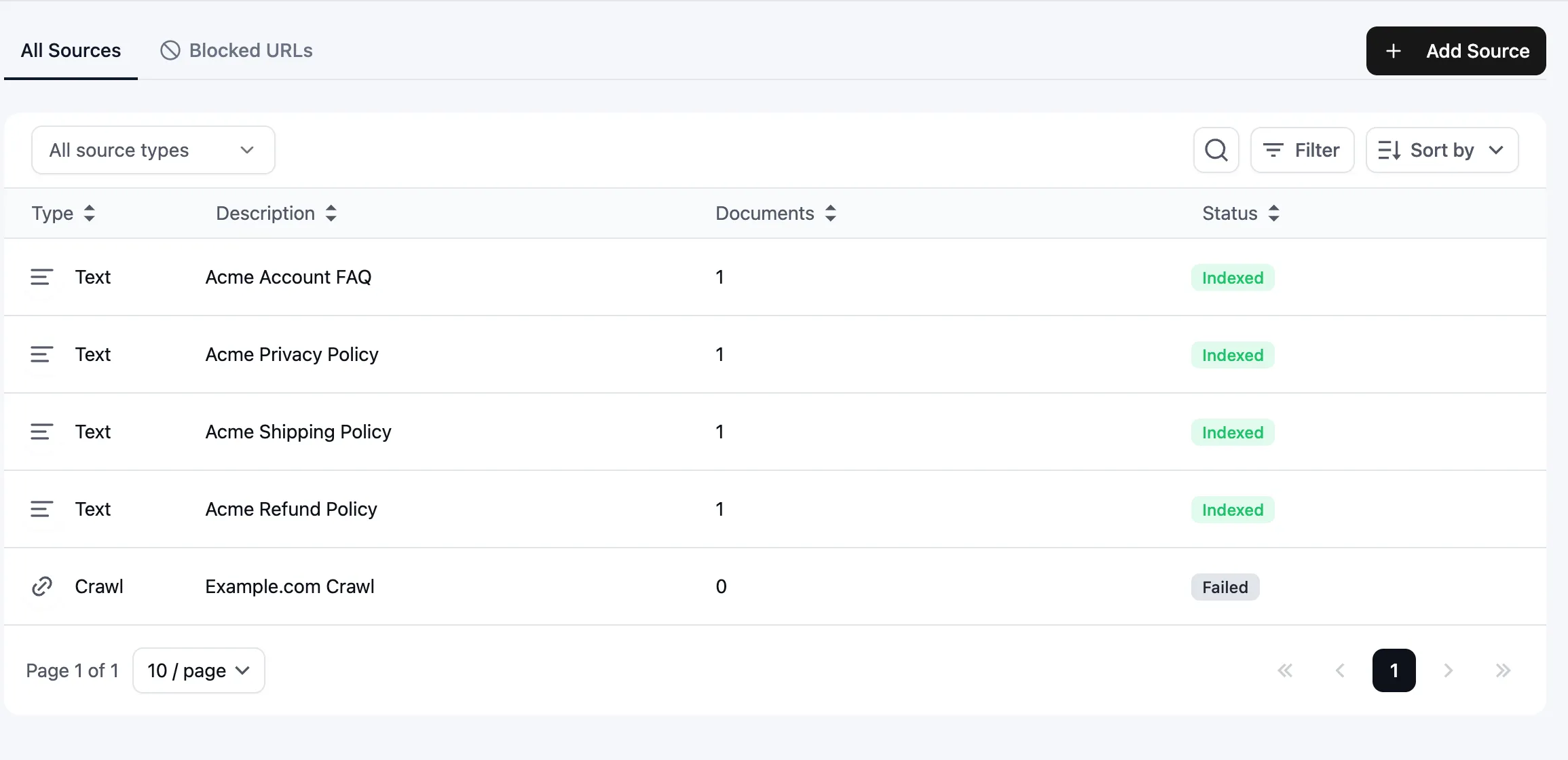
Source vs. document
- Source - what you add (a URL, a sitemap, a file, a Text paste). Has a status (Indexed / Failed / Partially Indexed / Scraping / Indexing / Queued / Deleting).
- Document - one indexed unit produced by the source. URL-based sources usually create one document per page. Text creates one document per paste. File sources can create one or more documents because large files are split into chunks.
The bot dashboard tracks both source count and indexed document count.
Choosing a source type
| Goal | Use |
|---|---|
| Index every page on a site | Sitemap if there’s one, otherwise Crawl |
| Index one public page | URL |
| Index a curated list of public pages | URL List |
| Add a PDF, TXT, or Markdown file | File |
| Add short internal text | Text |
| Index a GitHub repository | GitHub Repo |
| Index code without connecting GitHub | Codebase (zip) |
| Use existing Fluent Support tickets | Fluent Support |
You can mix any combination on one bot.
Status flow
Sources move through status states on the Sources page.
Common states:
Queued- waiting to start.Scraping- fetching website content.Indexing- preparing content for answers.Indexed- ready for the bot to use.Partially Indexed- some content worked and some failed.Failed- no usable content was indexed.Deleting- cleanup is running.
Open a source row to see details, failures, and retry options.
Plan limits
The PAGES counter on the Billing page caps indexed documents across the team. Website pages usually map one-to-one, while large files can count as multiple chunks. When you hit the limit, new indexing is blocked until you delete sources or upgrade.
Text usually counts as one document. Files and website sources can count as one or more documents depending on their size and page count.
Refresh
Website Links, GitHub Repo, and Fluent Support sources can have a refresh schedule. Files, Text, and Codebase (zip) don’t change unless you replace them — re-upload a new zip to update a Codebase source.
On refresh:
- Website pages are re-fetched.
- GitHub repos are re-checked, and only changed files are re-indexed.
- Changed content is updated.
- New sitemap or crawl pages can be added.
- Missing or removed pages and files are removed from the index.
See Retrain & Update for refresh and retry guidance.
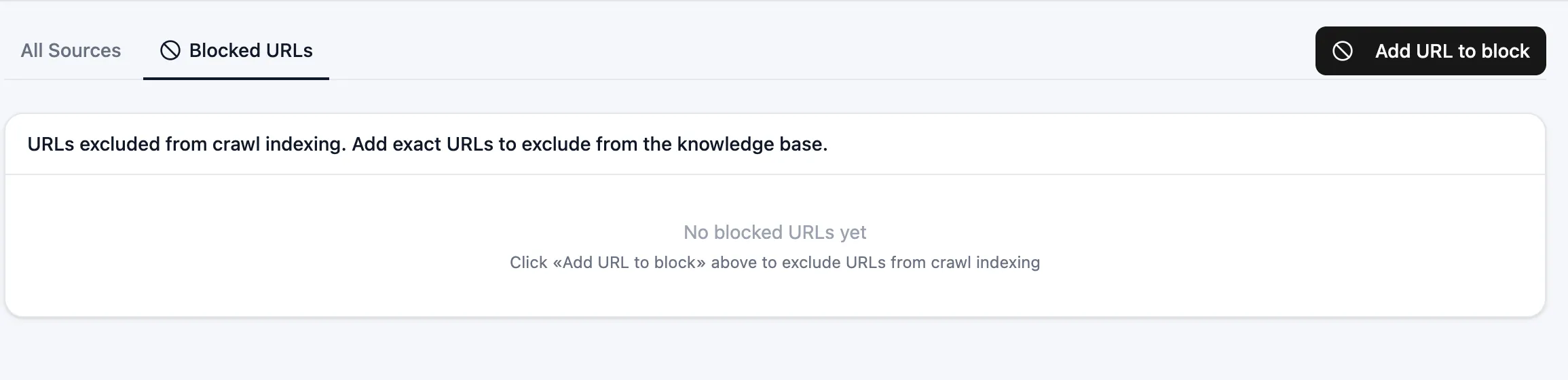
Blocked URLs
A per-bot deny-list applies across every Website Links source. Add URLs the crawler should never index, such as careers pages, login walls, or marketing-only sections that confuse answers.
Manage from Knowledge Base > Blocked URLs (see Sources).
What’s next
- Train your bot - the full add-source walkthrough.
- Sources - manage existing sources and statuses.
- Retrain & Update - keep content fresh.